Almost every engineering organization in the world is now experimenting with AI in software testing. Very few are getting meaningful results at scale. That contrast is the story of 2026, and if you lead a QA function, run an engineering organization, or sit on a technology leadership team, it is the most important operational reality you need to understand right now.
According to the 17th edition of the World Quality Report published by Capgemini and OpenText in November 2025, nearly 90% of organizations are now actively pursuing generative AI in their quality engineering practices. Only 15% have achieved enterprise-scale deployment. That 75-point gap is not a capability problem. It is a strategy problem. Organizations that have crossed from pilot to production share specific structural decisions in common, and those decisions are neither expensive nor exotic. They are, however, deliberate.
This playbook covers what AI in software testing actually does, where the real ROI lives, how the organizations that have scaled made it work, and what the leadership decisions look like at each stage. It is written for technology leaders making decisions, not for engineers looking for a framework comparison. If you want to know which tools to evaluate, that conversation starts here. But first, you need to understand what you are actually investing in.
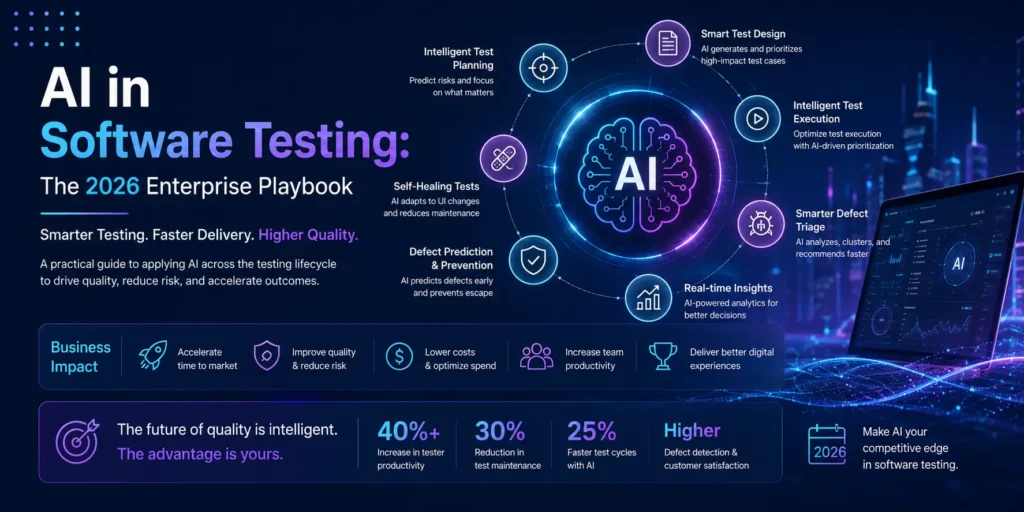
Table of Contents
The Real Problem That AI in Testing Is Solving
Before getting into capabilities and deployment patterns, it is worth being honest about the economic baseline that makes this conversation urgent.
Software testing is an enormous cost center in most enterprise organizations. A 2024 study found that, as of the most recent measurement period, approximately 23% of a company’s annual IT budget is dedicated to QA and testing. The World Quality Report has historically put that figure even higher for large-scale software organizations. That is a significant allocation for a function that, in most organizations, still runs a substantial portion of its work manually. According to the State of Quality Report 2025, which surveyed 1,400 QA professionals, 82% of testers still use manual testing in their day-to-day work. This is not because automation has failed. It is because the current generation of test automation, the frameworks built on Selenium, Cypress, and similar tools, carries a maintenance overhead that quietly consumes the efficiency gains it was supposed to create.
The World Quality Report 2025 documents test maintenance consuming between 30 and 40 percent of QA capacity at organizations running active UI automation. Think about that for a moment. Nearly half of your testing function’s capacity is not writing tests, not finding defects, not improving quality. It is maintaining tests that already exist against an application that keeps changing. This is the real problem. AI in testing is most valuable not as a novelty or a way to generate test scripts faster. It is valuable because it attacks the maintenance burden directly and simultaneously pushes defect detection to earlier points in the development lifecycle where fixing defects costs a fraction of what they cost in production.
The IBM Systems Sciences Institute’s Rule of 100 is well established: a defect fixed during design costs one unit of effort; the same defect found after release costs up to 100 units. NIST research and subsequent studies have repeatedly confirmed the directional truth of this cost curve even as specific ratios are debated. According to Gartner, for enterprise-level companies, the average cost of a single hour of critical application downtime exceeds $300,000, with major outages surpassing $1 million per hour. The financial case for catching defects earlier is not theoretical. It is one of the most empirically solid arguments in software engineering.
AI in testing addresses both sides of this equation simultaneously. It reduces the cost of maintaining existing tests while improving the probability of finding defects before they reach production. That is the core value proposition, and everything else follows from it.
What AI in Software Testing Actually Does
There is a tendency in technology media to describe AI testing capabilities in vague, capability-adjacent language that sounds impressive but tells practitioners nothing useful. This section cuts through that. Here is what AI systems in software testing are concretely doing in production environments today.
Autonomous and AI-Assisted Test Generation
AI systems can now generate test cases from multiple input types: natural language requirements, user stories, API specifications, existing source code, and recorded user sessions. The quality of the generated tests varies significantly by tool and context, but mature implementations are producing test suites that cover functional paths a human tester might not think to script until a defect surfaces.
The more valuable application of AI test generation is not generating tests from scratch but generating the tests that human authors consistently miss. Requirements documents contain implicit behaviors and edge conditions that are obvious to a system analyzing language patterns across thousands of prior defects but invisible to a tester reading a single document. AI-assisted test generation is at its best when it augments human test design, not when it replaces it entirely.
According to the State of Quality Report 2025, 72% of QA professionals are now leveraging AI for test generation and script optimization. That adoption rate reflects genuine utility, not hype. The caveat is that effective AI test generation requires clean, structured input. Organizations with well-maintained requirements documentation and API specifications see dramatically better results than those feeding the system from informal sources.
Self-Healing Test Infrastructure
This is arguably the single highest-impact AI capability in practical enterprise testing today. Self-healing tests use machine learning to identify why a test has failed, distinguish between a genuine defect and a test that has broken because the UI or API has changed in a non-breaking way, and automatically update the test to match the new application state.
The practical effect is significant. When a UI change that touches element identifiers, CSS classes, or page structure would previously break hundreds of tests and require days of manual intervention, a self-healing system resolves the majority of those failures autonomously. The 30 to 40 percent of QA capacity currently consumed by test maintenance begins to compress.
This capability has limits. Self-healing systems are not infallible, and they should never be left to operate without a human review loop. An AI system that silently “heals” a test that was actually catching a real defect is worse than a broken test. Organizations deploying self-healing infrastructure need explicit governance around what changes trigger automatic repair versus what changes require human review. That governance layer is where many pilots fail.
Predictive Defect Analysis and Risk-Based Test Selection
AI systems trained on historical defect data, code change patterns, and test result histories can predict which areas of a codebase are most likely to contain defects in a given release. This capability, often called predictive risk-based testing, allows QA teams to prioritize test execution toward the highest-risk areas rather than running the full regression suite on every build.
In mature implementations, this translates directly to faster release cycles without sacrificing defect detection rates. The State of Quality Report 2025 identifies increasing automation coverage and investing in AI and ML as the leading strategies for scaling QA, with 72.88% and 67.16% of respondents citing each respectively. Risk-based test selection is one of the clearest operational expressions of that strategy. Rather than asking your full regression suite to run against every commit, you are asking an AI system to tell you which subset of that suite is most relevant to the specific changes in this build.
Intelligent Test Orchestration and Parallel Execution
Beyond individual test capabilities, AI is changing how enterprise testing infrastructure is orchestrated. Intelligent test orchestration systems analyze test dependencies, failure patterns, and infrastructure availability to schedule and parallelize test execution more efficiently than static configuration allows.
The practical outcome is faster feedback cycles. A regression suite that previously took eight hours in sequential execution may complete in under two hours with intelligent parallelization, without requiring a proportional increase in infrastructure spend. For organizations targeting continuous testing within their CI/CD pipelines, this class of capability is often the prerequisite that makes everything else viable.
AI-Driven Root Cause Analysis
When tests fail in a large test suite, identifying the root cause has historically been a time-consuming investigative process. AI-powered analysis systems can correlate test failures across a suite, identify common failure signatures, trace failures to likely source code changes, and dramatically reduce the time from failure detection to developer notification of a probable root cause.
This capability shortens the feedback loop between a failing test and a developer fix, which is critical for organizations trying to maintain fast release cadences without increasing defect escape rates.
The Economics: Where the Real Return Lives
Forrester’s Total Economic Impact methodology, applied to enterprise test automation programs, documents a 4.5x ROI over three years with an average payback period of 13 months. That is the benchmark for well-implemented programs. AI-augmented programs are beginning to show faster payback periods, particularly for organizations extending existing automation with self-healing and predictive capabilities rather than rebuilding from scratch.
The economics work through several levers, and it matters which levers you focus on when building a business case.
The most significant lever is defect avoidance. NIST’s research framework and IBM’s Rule of 100 establish the same directional truth: defects found later are exponentially more expensive to fix. If AI-assisted testing improves defect detection rates at the unit and integration testing stage, the avoided cost of production defects often dwarfs the direct cost savings from automation efficiency. When building a business case for AI testing investment, the single most powerful number is not how many testing hours you save. It is how many production incidents you prevent, multiplied by the average cost of those incidents. For most enterprise organizations, that calculation is far more compelling than any efficiency argument.
The second lever is maintenance cost reduction. World Quality Report data puts test maintenance at 30 to 40 percent of QA capacity. If self-healing infrastructure reduces that by even 50 percent, the released capacity can be redirected to coverage expansion, exploratory testing, or quality engineering work that creates direct business value. The compounding effect of this reallocation over a 12 to 18 month period tends to show up in release velocity metrics before it shows up in direct cost figures, which is why you need to track both.
The third lever, which is frequently overlooked in ROI modeling, is Capgemini’s documented insight that test maintenance costs inflate significantly in years two and three of traditional automation programs as test suites grow and maintenance debt compounds. AI-assisted programs with self-healing infrastructure show a flatter maintenance cost curve over time. A business case that models only year-one costs and year-two savings, without projecting maintenance cost inflation under the status quo, consistently understates the three-year return of AI investment.
One important caution: a significant number of organizations report positive ROI from test automation generally but struggle to attribute it precisely. The State of Quality Report 2025 found that only 36% of surveyed organizations report positive ROI from their automation programs. That lower-than-expected figure reflects programs that were implemented without clear measurement frameworks, not programs that failed to generate value. You cannot improve what you do not measure. Establishing baseline metrics before deployment is not a bureaucratic exercise. It is the foundation of a defensible business case.
Five Deployment Patterns That Actually Work at Enterprise Scale
AI testing capability is not a single product you buy and deploy. It is a set of capabilities you integrate into an existing testing function at points where they generate measurable value. These five deployment patterns represent the ones organizations are actually succeeding with at enterprise scale in 2026.
Pattern 1: AI-Augmented Regression on a Bounded System
The safest entry point for most organizations is selecting a single application or system with a well-defined regression suite and applying AI augmentation to that suite. This means adding self-healing to reduce maintenance overhead, applying predictive prioritization to focus execution on high-risk areas, and using AI-assisted root cause analysis to shorten failure investigation cycles.
This pattern works because it is bounded. Success is measurable, failure is contained, and learnings are transferable. Organizations that start with a full-portfolio AI testing transformation almost universally regret it. The complexity of coordinating across teams, integrating with multiple legacy systems, and managing organizational change simultaneously is sufficient to derail programs that would have succeeded with a more patient sequencing.
Pattern 2: Autonomous Test Generation from Requirements and Specifications
For teams with high-quality requirements documentation or well-maintained OpenAPI specifications, AI test generation can be deployed as a parallel process alongside human test design. The AI system generates a candidate test suite from the specification; human testers review, select, and supplement that suite; the combined output goes through standard review before entering the regression suite.
This pattern accelerates coverage expansion without requiring proportional headcount growth. It is particularly valuable for teams absorbing new applications or system integrations that would otherwise require a significant investment in manual test authoring before coverage reaches an acceptable threshold.
Pattern 3: Self-Healing Infrastructure at the Platform Level
Rather than deploying self-healing as a feature of individual tests, mature organizations are implementing it at the infrastructure level, where it applies uniformly across the entire test suite. Platform-level self-healing means applying consistent governance, consistent logging, and consistent human review checkpoints across all automated tests rather than managing healing behavior tool-by-tool.
This pattern requires investment in the governance layer before it delivers full value. Organizations that skip governance, and simply turn on self-healing without defining what changes require human confirmation, create the risk of silent test degradation. That risk is real and manageable, but only if governance is designed upfront.
Pattern 4: Predictive Risk-Based Test Selection Integrated into CI/CD
This pattern requires the most investment in data infrastructure but delivers the most direct impact on release velocity. Implementing predictive test selection means collecting and structuring historical data on defect locations, code change patterns, test coverage mapping, and failure histories; training a model on that data; and integrating the model’s output into the CI/CD pipeline so that every build triggers a dynamically optimized subset of the test suite rather than a static one.
The payoff is significant. Regression cycles that currently gate release schedules can be substantially compressed without increasing defect escape rates, because the tests running are the ones most relevant to the specific changes in the build. This is not test coverage reduction. It is test coverage optimization.
Pattern 5: AI-Driven Quality Intelligence for Leadership Visibility
This is the pattern that matters most for engineering leadership even if it is rarely framed as an AI testing initiative. AI-driven quality intelligence systems analyze testing data across the full development pipeline to surface actionable insights for decision-makers: which teams are generating the most defects, which system areas carry the highest release risk, where coverage gaps are growing, and how quality metrics are trending relative to business velocity.
This transforms quality data from a reporting artifact into a decision-support tool. CTOs and VPs of Engineering who currently receive weekly defect counts begin receiving predictive risk signals that inform sprint planning, architecture decisions, and resource allocation. That shift in how quality information flows to leadership is often the most durable value that AI testing investment creates.
What the 15% Who Have Scaled Did Differently
The World Quality Report 2025 finding that only 15% of organizations pursuing AI in quality engineering have achieved enterprise-scale deployment is a useful diagnostic. Understanding what separates that 15% from the 85% who are stuck in pilot is more useful than any tool evaluation.
The first difference is that the organizations that scaled treated governance as a prerequisite, not an afterthought. AI testing systems operate at a speed and scale that makes manual governance impossible once you are in production at enterprise level. The organizations that established clear policies before deployment, covering what the AI system can change autonomously, what requires human review, and what should never be modified without explicit approval, were the ones that maintained leadership confidence through the scaling process. The ones that deferred governance built systems that leadership eventually stopped trusting.
The second difference is that none of them replaced their QA team with AI. This point deserves more emphasis than it typically receives in the analyst literature. Every organization that has successfully scaled AI in testing has done so by redirecting QA capacity rather than reducing it. Self-healing freed testers from maintenance. Predictive prioritization freed them from running full regression suites. AI-generated tests freed them from initial script authoring. The time recovered was reinvested in exploratory testing, quality engineering architecture, and test strategy work that AI cannot do because it requires the kind of contextual judgment that comes from knowing the business domain. Organizations that used AI to justify headcount reduction almost universally saw test quality degrade within 18 months.
The third difference is that they measured differently from the start. Traditional QA metrics, test case counts, defect counts, and test execution rates, do not capture the value AI testing creates. The organizations that succeeded established new measurement frameworks before deployment: defect escape rates, mean time to detect, test suite maintenance cost as a percentage of QA capacity, and deployment frequency as a function of test cycle time. These metrics tell a story that connects testing investment to business outcomes. Without them, AI testing investment looks like cost without return.
The fourth difference is that they built for explainability. Engineering teams that do not trust test results will not act on them, and AI-generated or AI-modified test results are inherently more suspect than tests written by a known human author. The organizations that scaled AI testing successfully invested in making their AI systems’ decisions interpretable. When a self-healing system modifies a test, there is a log entry that explains what changed and why. When a predictive system selects a subset of tests, there is a rationale that a human engineer can review. That transparency is not a luxury. It is the mechanism through which trust is built incrementally until AI testing results carry the same operational weight as human-authored test results.
Three Failure Modes That Derail AI Testing Programs
Understanding why programs fail is as important as understanding what success looks like. Three failure modes account for the overwhelming majority of AI testing programs that stall, get abandoned, or quietly fail to deliver value.
Treating AI Testing Tools Like Traditional Automation Frameworks
The procurement and deployment patterns for AI testing tools are often modeled on the patterns organizations used for traditional test automation frameworks, and that mismatch creates serious problems. Traditional frameworks are configured once and then maintained. AI testing systems need to be trained, monitored, and improved continuously. They produce outputs that need to be evaluated and calibrated. They require ongoing data input to maintain accuracy as applications evolve.
Organizations that buy an AI testing tool expecting a one-time implementation followed by passive value generation are consistently disappointed. The ones that approach it like any other AI system, with a feedback loop, a measurement framework, and a team responsible for improving it, capture the actual value.
Read: Top 10 Software Testing Tools Every Tester Should Know
Skipping Test Data Governance
AI testing systems are only as good as the data they operate on. Test data governance, defining what data is available for testing, how sensitive data is handled, and how test data environments are kept realistic, is a prerequisite for AI testing that many organizations defer because it is less exciting than the capability conversation. The World Quality Report 2025 identified data privacy risks as the top barrier to AI adoption in quality engineering, cited by 67% of respondents. That figure is not surprising. AI testing systems that operate on production data without adequate privacy controls create compliance exposure. AI testing systems that operate on synthetic or masked data that does not reflect production behavior produce test results that do not predict production defects. Resolving this tension requires deliberate test data governance, not a tool purchase.
No Human Review Loop
This is the failure mode that creates the most serious quality consequences. AI systems make mistakes. Self-healing systems misclassify real defects as test maintenance issues. Predictive systems deprioritize tests that would have caught critical failures. Test generation systems produce tests that cover the wrong behavior. These errors are manageable if a human review loop is in place. They compound into systemic quality problems if they are not.
The organizations that fail because of this pattern typically failed because they were attracted to AI testing for the promise of reduced human oversight, not increased capability. That is a fundamental misreading of the value proposition. AI in testing extends what human testers can do. It does not eliminate the need for human judgment at the boundaries.
Building Your AI Testing Roadmap: 90 Days to Proof of Value
Organizational transformation that takes 18 months to show results gets defunded. The following 90-day structure is designed to produce demonstrable, measurable proof of value within a single quarter while laying the architectural foundation for enterprise scaling.
Days 1 to 30: Baseline and Selection
Begin by establishing a quantitative baseline for the system you intend to pilot. Measure current test maintenance time as a percentage of QA capacity, current regression cycle duration, current defect escape rate to production, and current test coverage by system area. These numbers will be the baseline against which you measure improvement. Without them, you cannot make a defensible case for continued investment at the end of the quarter.
Select the application or system for your pilot based on two criteria: it should have an existing automated test suite of meaningful size, because AI augmentation needs something to augment, and it should have a stable enough codebase that results will reflect tool performance rather than development instability. Brownfield systems with stable architectures are often better pilot candidates than greenfield systems in active development.
Evaluate two or three AI testing tools against your specific baseline metrics and integration requirements. Gartner published its first Magic Quadrant for AI-Augmented Software Testing Tools in October 2025, which provides a useful starting frame for the capability landscape. Tool selection should be driven by your specific environment, existing toolchain, and the specific failure modes you are targeting, not by analyst rankings alone.
Days 31 to 60: Instrumented Pilot
Deploy the selected tool against your pilot system with full instrumentation from day one. Every AI decision should be logged. Every automatic test modification should be flagged for human review. Every predicted risk score should be recorded alongside actual outcomes. This is how you build the dataset you will need to evaluate performance and make the case for scaling.
Run a parallel operation during this phase: the AI-augmented system and the existing process running simultaneously, with results compared. Parallel operation adds cost and complexity but eliminates the ambiguity of causality when you are measuring results at the end of the quarter. If the AI-augmented system catches a defect that the traditional process missed, you have documented evidence. If it produces a false self-heal that would have missed a real defect, you have caught it before it caused damage.
Days 61 to 90: Measure, Present, and Expand
At day 61, stop parallel operation and transition the pilot system to AI-augmented-only. Use the final 30 days to accumulate outcome data: test maintenance time reduction, regression cycle duration, defect escape rate changes, and any production incidents in the pilot system compared to historical baseline.
At day 90, present findings to engineering leadership with the explicit intention of securing approval for the next phase of scaling. Frame the presentation around business outcomes, not testing metrics. Reduced time to release, reduced production incident costs, increased engineering capacity redirected to feature work. If the pilot has been well-instrumented, you will have the numbers to make that case clearly.
If the pilot has not delivered measurable improvement, that is also valuable information. The 90-day structure is designed to surface failure early, when the cost of course correction is low.
What This Changes About Your QA Team
The organizations that have successfully scaled AI in testing have each gone through a version of the same organizational transition, and understanding that transition is important if you are responsible for a QA team that will be affected.
The role that is most directly transformed by AI testing is not the manual tester. It is the test automation engineer whose primary responsibility has been maintaining an existing automated test suite. Self-healing infrastructure significantly reduces the manual maintenance burden that defines that role. Organizations facing this transition need to actively support the evolution of those team members toward quality engineering work that AI cannot do: defining test strategy, designing test architectures, developing test data frameworks, conducting exploratory testing, and serving as quality advocates in product and engineering conversations.
The role that AI testing creates demand for, and that is currently undersupplied in most markets, is the quality engineer who can work at the intersection of AI systems and testing practice. This is someone who understands how to evaluate AI test outputs, how to configure and tune AI testing systems, how to design governance frameworks for AI testing decisions, and how to connect testing outcomes to business metrics. This is not an automation engineer with AI tooling. It is a distinct role that combines quality engineering judgment with AI systems literacy.
The title “QA tester” describes what a person tests. The title “quality engineer” describes what a person builds. The transition from the former to the latter, at an organizational level, is accelerated by AI adoption and is one of the defining professional developments of the next five years in software engineering. Engineering leaders who understand this transition and actively develop their teams toward it will find that AI testing investment and talent retention reinforce each other.
The Questions Every CTO Should Be Asking Their QA Lead Today
If you are a technology leader who does not run a QA function directly but is responsible for one, the following questions will give you a fast, reliable read on where your organization sits relative to the 15% who have successfully scaled AI testing.
What percentage of our QA team’s time is spent maintaining existing automated tests? Anything above 25% is a signal that the maintenance burden has grown to a level where AI self-healing infrastructure would pay for itself quickly. The World Quality Report documents this figure at 30 to 40 percent in organizations with active UI automation. If your QA lead does not know this number, that itself is diagnostic.
How long does our full regression suite take to run, and is that duration currently gating releases? Regression cycle time is one of the clearest measures of whether testing infrastructure is keeping pace with delivery velocity. If the answer is measured in hours, predictive test selection is almost certainly worth evaluating.
What is our defect escape rate, and has it changed as our release cadence has increased? This is the number that connects testing performance to business outcomes. Rising escape rates as delivery velocity increases is the signature of a testing function that is not scaling with the development function. AI testing directly addresses this.
Where are our highest-risk system areas, and how is our test coverage mapped against that risk? If the answer involves human judgment without data, the organization is missing the predictive infrastructure that AI testing can provide. If the answer involves a dashboard that is updated quarterly, that is better but still insufficient for the pace of modern development.
What would it take for you to cut our regression cycle in half without increasing defect escape rates? This question surfaces whether your QA lead is thinking about the problem architecturally or operationally. The answer should involve AI-assisted test prioritization and parallel execution strategy. If it involves more testers or more test infrastructure, the architectural conversation has not happened yet.
Where This Goes From Here
The 90-to-15 split documented in the World Quality Report 2025 will narrow over the next 24 months, but not because AI testing becomes simpler. It will narrow because the organizations that have scaled will have built enough institutional knowledge to advise, consult, and compete against organizations that are still running pilots. The competitive advantage of earlier movers in AI testing is not permanent, but it is real and it is currently underappreciated in the analyst commentary on this space.
The next material development in AI testing that enterprise leaders should be tracking is the testing of AI systems themselves. As generative AI becomes an active component of the products your engineering teams are building, the question of how to test an AI feature, one that produces non-deterministic outputs, that learns from user interaction, and that may behave differently depending on the version of the model underneath it, becomes urgent. The frameworks for testing traditional software do not translate directly to AI-powered software. A substantial portion of the intellectual work in quality engineering over the next three years will be developing those frameworks. Organizations that build that capability early will find that it serves both their internal AI adoption and their competitive product differentiation.
The core insight that should guide every decision in this space remains the same insight that has guided quality engineering since Barry Boehm published his research in 1981: the cost of quality failure grows exponentially with time. AI testing is the most powerful set of tools the profession has ever had for catching failures earlier, at lower cost, with higher confidence. The 15% of organizations that have figured out how to use those tools at scale are not operating in the same economic reality as the 85% who are still treating it as an experiment. The playbook for closing that gap is not complicated. It requires clear measurement, bounded pilots, patient sequencing, governance before scaling, and a genuine commitment to developing the team alongside the technology.
The organizations that get this right will not just have better testing. They will have faster releases, fewer production incidents, lower engineering costs, and higher user satisfaction. Quality, done at this level, is not a constraint on delivery. It is a competitive capability.
Key Takeaways
For engineering leaders reviewing this material and making near-term decisions, the following points summarize where the highest-confidence investments lie.
The World Quality Report 2025 documents that nearly 90% of organizations are pursuing AI in quality engineering but only 15% have reached enterprise-scale deployment. The gap is strategic, not technical. Organizations that scaled established governance before deploying, measured business outcomes rather than testing metrics, and redirected rather than reduced QA team capacity.
AI testing’s highest-impact near-term applications are self-healing test infrastructure, which reduces the 30 to 40 percent of QA capacity currently consumed by test maintenance, and predictive risk-based test selection, which compresses regression cycle times without increasing defect escape rates.
The business case for AI testing investment is strongest when it centers on defect avoidance cost rather than efficiency gains. The Rule of 100, validated across IBM and NIST research, establishes that production defects cost orders of magnitude more than defects caught during development. Preventing a material fraction of production incidents through earlier detection dwarfs the direct operational savings from automation efficiency.
The 90-day pilot structure outlined in this article is designed to produce defensible, measurable proof of value within a single quarter, which is the practical threshold for securing continued investment approval in most enterprise organizations.
The question for engineering leaders is no longer whether AI changes software testing. It does, materially and durably. The question is whether your organization is structured to capture that change or to watch a widening gap develop between your testing function’s capacity and your development function’s velocity.
Sources Referenced
- World Quality Report 2025, 17th Edition. Capgemini, Sogeti, and OpenText. November 2025.
- State of Quality Report 2025. Katalon. Survey of 1,400 QA professionals.
- IBM Systems Sciences Institute. Relative Cost of Fixing Defects (Rule of 100).
- Gartner Magic Quadrant for AI-Augmented Software Testing Tools. October 2025.
- Forrester Total Economic Impact Methodology. Enterprise test automation benchmark data.
- NIST. Software Testing Infrastructure research (original 2002; directional validation in subsequent studies).
- IBM Cost of a Data Breach 2024. Average enterprise downtime cost data.